网站运营中有一个环节至关重要,那就是数据监控及数据分析,否则出问题都不知道出在哪里。而爬虫日志分析做为数据监控及分析的一部分是所有SEO技术中最基础的,但是却不是最简单的。说基础是因为所有的科学的SEO策略都必须依赖于数据分析,而日志是为数不多的能直接了解搜索引擎和我们网站发生了哪些交互的渠道之一而且是流量到达之前的第一手数据。说不简单是因为数据的存储及处理上,日志从几十MB,几百MB,几个GB,几十个GB,几百个GB,几个TB用到的工具及部署难度是完全不同的:几十MB用ultraedit等文本编辑器都可以做到数据的拆分;几百MB的时候得用shell;而如果是几个GB可以开始考虑利用Mysql或者其他行存储的数据库来存储字段切分后的结构化日志了;几百个GB可以上Infobright或者其他列存储的数据库了;如果达到TB那只有Hadoop的hive能够解决了,目前在用Hive的SEOer我所知道的只有赶集网的zero大神了。

对于99%的站长朋友来说,shell用于处理日志已经很称职了,我目前用的也是shell。这里简单介绍一下shell的概念,shell可以理解成*nix系统的cmd命令行,而日志拆分中常用的shell指令有cat以及awk(实际上grep用的也很多,只是本文为了控制篇幅就不多介绍了)。cat实际的作用是合并多个文件并且将标准输出(stdout)的结果打印到屏幕上。而awk指令其实当成编程语言都可以写一本书的,他的特色就是可以按照分隔符切分文本字段并且处理,默认的分隔符为空格。以上两个指令网上资料一堆,建议各位都花时间学习一下。
言归正传,作为网站运营的数据据监控体系的一部分,我们公司建立一个全自动爬虫日志分析的系统,功能上可以参考夜息的博文来看。全自动化日志分析脚本很好的起到了监控及预警的作用,但不是万能的,日志如果出现莫名其妙的错误,就还是得自己动手丰衣足食。在去年12月第二周的周日志监控报表中,百度爬虫的301及302响应码的抓取量大幅增长,这部分异常抓取量加一起一周涨了6w!因为一定时间内蜘蛛的抓取量是恒定的,那么错误页面的抓取上涨代表着其他页面抓取的下降,在本例中,内页受影响最大。抓取量发生如此剧烈波动意味着肯定有地方出问题了,所以我们第一步需要确定的是具体哪些页面出现了问题。
贴一条日志记录(目的是帮助大家定位下面实例中awk具体的域分别是哪些,由于有竞业保密协议,所以下面的关键部分我打码了):
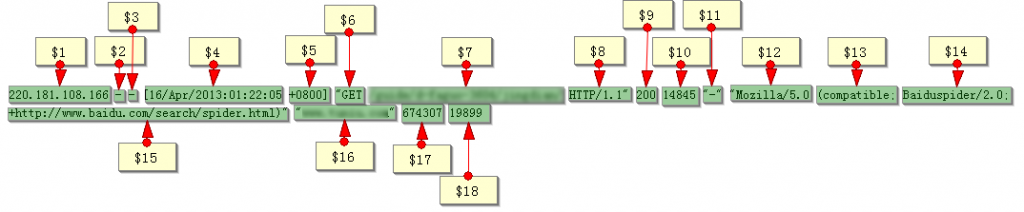
接下来开始工作了,我们首先构造第一个指令进行查询:根据上面的日志我们可以知道利用awk分析日志时HTTP状态码位于第九域也就是$9,而URI位于$7,那么首先我们合并上周的日志,从中提取出所有状态码为302的日志,同时将域名及URI进行合并成完整的URL,最后我们拆分出返回302状态码最多的TOP10个的二级目录,按访问次数降序排序。由于当时忘了截图了,所以现在就手打下面的代码供各位参考:
- cat 20121203.txt 20121204.txt 20121205.txt 20121206.txt 20121207.txt 20121208.txt 20121209.txt | awk '{if($9 ~ "302")print $16$7}' | awk -F"\/" '{print $2}' | sort | uniq -c | sort -nr | head -n10
【本篇文章来自道哥博客http://www.seodug.com/,您看到的可能只是采集的结果,原主题会不断更新以提供高质量的内容,如果您想看到更多100%原创,高质量,一线实战SEO的分享和分析请到道哥博客http://www.seodug.com/】
在10个结果中发现abc(好吧,我可耻的打码了)这个二级目录格外抢眼,数量达到了2W,同时我对比了上上周302的数据,发现之前abc目录也有302的问题,只是数量级在1K左右,而且之前abc目录下返回302的页面是完全正确的。至此我开始怀疑abc二级目录下存在有异常情况,同时由于abc二级目录下的页面数量依旧众多,我们如果要知道是具体哪类页面有问题的话,还是得进一步往下细分。我的思路很简单,继续挖URL的目录层级确定问题出现的位置。
1,先计算abc目录有多少次跳转被百度爬虫抓取到

2,多加一个判断条件,判断出问题的URL目录层级具体是第几层日志分析及网站运营改进实例 2
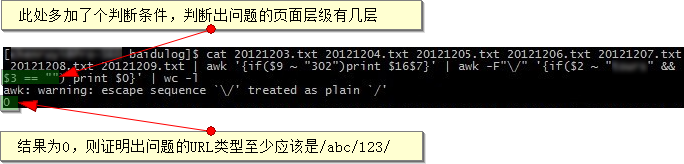


3,在发现了出错的URL的目录层级后,我们将这部分出错的URL提取个100条出来看看
- cat 20121203.txt 20121204.txt 20121205.txt 20121206.txt 20121207.txt 20121208.txt 20121209.txt | awk '{if($9 ~ "302")print $16$7}' | awk -F"\/" '{if($2 ~ "abc" && $4)print $0}' | head -n100
通过上面的查询发现了在不同二级域名的abc目录下都存在同类错误URL(如domainname/abc/123/123)被爬虫抓取到,那么可以肯定这个一定是个批量存在的问题,而且是模板上有错误导致大量页面受影响,而绝不是个别页面出错。
既然如此我们可以顺藤摸瓜了,最终发现问题是出现在了产品页的相关产品链接模块上,在前一周上线相关功能时研发部同事为了省事,直接将此处的a标签写成了这种格式的相对路径(<a href=”123456″>xxx</a>),那么当用户访问的当前URL为domainname/abc/123的情况下这类相对路径在补全之后会变成domainname/abc/123456,这个URL是正确的。但不巧的是,上线该功能的时候研发同时调整了rewrite规则,导致原先domainname/abc/123/这种不规范URL301跳转到标准化的不带斜杠的URL规则由于被覆盖而失效了,结果就是domainname/abc/123/竟然返回了200代码,而要命的是,相对路径在这种情况下就被补全为domainname/abc/123/123456了,也就是我们日志分析中最后发现的错误URL形式。而这类错误的URL则又莫名其妙的匹配到了301和302的rewrite规则,于是乎错误抓取量一发不可收拾。当时的截图如下:

既然问题根源已经找到了,接下来就是制定解决方案:
- 修改产品页模板:对相关产品链接使用根目录起始的相对路径(也就是<a href=”/abc/123456″>xxx</a>);
- 增加URL标准化的rewrite规则:将带斜杠的网址301到不带斜杠的标准网址(Rewriterule ^/abc/([0-9]+)/$ /abc/$1 [R=301,L])
- 由于百度对301反应很慢,所以需要利用百度站长平台中的网站改版工具的高级改版规则来加强URL标准化效果:替换规则为abc/#/<>,然后再填入两个样例帮助百度匹配下即可。这里可以简单说一下,替换规则中的#代表着任意数字,在我们这个实例中代表产品页的数字id,而最后的<>则是将<>中的内容,此处其中为空,直接替换掉最近匹配到的文字,也就是URL结尾的斜杠。但是可惜的是如果遇到的标准URL是带斜杠的/abc/123/这种,那就没法使用百度改版工具来做了,因为目前的站长改版工具的规则很刻板,也不像正则可以用后向引用,所以这种情况就只有囧的份了。
- 优化网站运营流程:本篇文章写了很多的技术细节,以至于有点偏离运营优化的主题了,但是透过现象看本质,我写清楚这整个流程,是为了告诉大家这个问题发生的根本原因实际上是运营流程出了问题,因为这类错误本是可以避免的,是本就不该出现在线上的!上面的3个只是治标的方法,治本得从源头做起:一,优化整个网站的版本上线流程,网站上凡是涉及到前端代码更改的程序版本,都需要在测试通过后转由SEO人员做前端代码的质检,相当于二次确认,确认过后才能发布到正式环境;二,开展针对产研部门的SEO内训,并与产研部门建立起良好的沟通及信任关系(这要求SEO人员本身技术够硬,得能使研发信服,同时还得有优秀的人际交往技巧及人格魅力),提高产研人员对SEO的理解及重视程度,并将以前曾犯过的错误建立FAQ,保持更新。三,BUG与绩效挂钩。四,PUSH流程优化方案并落实。
最后总结:
- 数据(不仅仅是日志)的监控很重要,最好能每周整理成图表,重点看趋势线,其次才看绝对值;
- 将大数据一步步拆分到小数据的过程很重要;
- 一个良好的工作流程才是保证整个团队高效的重中之重;
题外话:
说道跳转还有个小细节要说一下,那就是多重跳转:A301到B,B301到C,C301到D等等,如果你网站的URL改版也很频繁的话这个问题你迟早会发现,因为研发的观点是不管跳2次还是3次还是100次,反正能跳到最后一个最新的页面了对他来说就行了。但对于SEO来说这是个要命的事情,因为几乎每多1次跳转你都在损失旧页面的权重传递百分比,matt cutts在youtube上的google webmaster专区谈到过这个问题,google能接受的范围也不过是one or two, maybe three,百度据我观察基本也是最多2次。回到运营流程的主题上来,如果研发每次遇到这类问题他都能意识到对SEO有潜在影响,并会主动问询,那你可想象在这样的公司做SEO是件多幸福的事情。
转载请注明:思享SEO博客 » 怎么通过分析网站日志改进SEO运营!